단톡방 자주 출몰하는 질문 정리
글들이 왜 깨지는지 모르겠습니다.
아래 링크에서 보시면 더 편합니다.
[링크][깃허브링크]: https://github.com/eat-toast/eat-toast.github.io/blob/master/_posts/2019-02-01-%20소심한%20나의%20답장.md
현재 오픈 카톡방에 들어가 있는 곳은 4가지가 있다.
- 캐글코리아 오픈채팅
- 데이터분석 질문답변 & 친목
- Python Data Science
- 파이썬 Python2./3.
이 중, 몇몇 단톡방에서 자주 출몰하는 질문들이 있어 정리하고 넘어가면 좋을 것 같아 기록하려고 한다.
추가로 나의 의견도 정리 해보려 한다. (소심하게 답장 해보는 나의 일기 정도 되겠다.)
one-hot-encoding
<캐글 코리아 2019-01-21>
- one-hot-encoding 은 꼭 필요할까요?
- 만약 필요하다면 왜 필요한 걸까요?
- 변수가 늘어나고 용량이 많이 쓰이는 것인데, one-hot-encoding이 그것의 단점을 극복할만한 필요성이 무엇일까요? 조언을 부탁드립니다.
* 자전거, 자동차 사람이 1, 2, 3에 대응된다면 아웃풋 자체의 순서나 스케일에 영향을 받을 수 있어 좋지 않다.
* 지나치게 순서나 스케일이 중요한 문제라면, 원핫 인코딩은 좋지 않다. (?)
* 차원이 늘어나는 것이 문제라면, Frequenct -Encoding 이나 mean encoding 또는 알고리즘에 built-in 카테고리 처리 방법을 쓴다.
* 딥러닝 에서는 entity embedding을 사용 한다.
결국, 범주형 변수를 처리하는 내용에 정답은 없으며 목적에 맞게 처리해야 한다.
그 목적이 Acc라면 모든 방법을 동원해 보고,
예측 보다는 설명이라면 Domain 지식에 알맞게 변수를 가공해야 함
## python <파이썬 Python2./3. 2019-01-22> ```python a = [0, 1, 2, 3] for a[-1] in a: print(a[-1]) ``` 위 코드의 결과는 0 1 2 2 다. 왜 그럴까? <답변내용>
기본 아이디어 : a[-1]에 a를 순차적으로 대입 (대입 이라는 개념이 있어야 한다.)
1회차에는 a[0]를 a[-1]에 대입해서 a가 [0, 1, 2, 0],
2회차에는 a[1]를 a[-1]에 대입해서 a가 [0, 1, 2, 1],
3회차에는 a[2]를 a[-1]에 대입해서 a가 [0, 1, 2, 2],
4회차에는 a[3]를 a[-1]에 대입하는데 a[3]이 2니까 a가 [0, 1, 2, 2],
나도 몰랐던 개념이다. 반복문을 이렇게 쓸 수(?) 있다니. 끝 자리만 바꿔가면서 반복문을 실행하고 싶을 때가 있을까 싶다.
문제를 위한 문제같은 느낌이다. 그래도 한 수 배웠다. ## python <Python Data Science 2019-01-23 (수)> ```python class C: def a(self, x): print(x) def b(self): a('출력') ``` C라는 클래스 선언 후, b함수 호출하면 에러가 난다. <답변내용> python에서 self 라는 개념을 알고 있어야 한다. (이 부분에 사진 다시 올리기) --> 아마 질문자는 C라는 클래스에서 b를 호출하면 a함수로 연결되고
a는 받은 것을 그대로 출력하니까 잘 되겠지 라고 생각했던 것 같다.
하지만, self를 쓰지 않으면 나(C 클래스)에 제대로 전달되지 않는다. 위 내용을 올바르게 정리한다면 아래와 같이 작성하면 된다. ```python class C: def a(self, x): print(x) def b(self): self.a('출력') ``` --- ## paper <위 목록에 없는 스터디 단톡방에 올라온 질문 2019-01-24 (목)> Image 분류 문제에서 TOP1이랑 TOP5가 의미하는게 무엇인가요? <답변내용> Top k의 경우 Softmax를 지났을 때 나온 값들을 k개 만큼 보고 판단 하겠다는 의미.
상위 k개 안에 정답이 있는 경우 정답으로 처리. k개 밖에 위치하는 경우는 오답으로 처리
일상적으로 말하는 ACC는 TOP1 error라고 볼 수 있다. --> 논문에서는 다양한 metric을 제시하곤 한다.
저자가 정의하기 나름인데 이미지 분류에서는 TOP1 과 TOP5 에러를 자주 사용한다.
--- ## python < python 2./3. 2019-01-25 (금) > EC2에서 아래 코드 실행 시, KST로 출력되지 않습니다.
``` python datetime.datetime.now(pytz.timezone('Asia/Seoul')).strftime('%Y-%m-%d %H:%M:%S') ``` <답변내용>
없음
--> 사실 이건 내가 올린 질문이다. 그리고 내가 찾은 답변은 [StackOverflow][stackKST]를 참고 했다.
KST시간을 얻기 위해서는 TimeZone 설정을 해야 한다.
```python import datetime import pytz seoul = pytz.timezone('Asia/Seol') datetime.datetime.now(tz = seoul) ``` 혹은 timestamp의 tz를 함수를 통해 변경할 수 있다. ```python datetime.datetime.now(tz = timezone.utc).astimezone(seoul) ``` --- ## Jupyter notebook <케글 코리아 2019-01-28 (월)> 주피터 노트북의 테마를 변경할 수 있는 방법이 존재한다. [link][주피터 테마 변경] 링크를 통해 얻을 수 있는 지식은 1. 테마 2. Snippets : 자주 사용하는 문구를 저장 후 바로 출력 3. Split Cells Notebook : Cell을 좌우로 둘 수 있다. (비교 시 유용) 4. Table of Content : 빠르게 해당 주제로 이동 할 수 있다.(논문 소단원 중단원 클릭시 이동하는 것과 같음) 5. Collapsible Headings: Cell을 주제 단위로 접을 수 있다. (R 의 ####과 비슷한 기능) 등 다양한 팁을 얻을 수 있다. 아직 시도는 안했다. (1/30 시도 후 포스팅) --- ## Math <Python Data Science 2019-01-29(화)> (3, 5] 이상 이하, 초과 미만 구분을 어떻게 하나요? <답변내용> 3 < x <= 5 --> 간단한 수학기호 질문으로, 3초과 5 이하를 기호로 표현한 내용을 담고 있다.
암기하는 ★나만의 꿀팁은★ () 괄호는 튀어 나와있어서 자기 자신을 담지 못해 = 가 없고
] 같은 대괄호는 나를 감싸주는 모양이라 = 를 포함한다. --- ## ML & DL Active learning 이란? <답변내용> - 스스로 찾음
언 라벨 데이터를 이용하는 방법이며, 자세한 내용은 NDC에서 발표한 자료를 참고하면 된다.
 현실세계에서는 라벨 데이터와 언라벨 데이터, 두 종류로 나뉜다. 1번 그림에서 보는 바와 같이 라벨이 붙어있는 데이터는 빙산의 일각이다.
현실세계에서는 라벨 데이터와 언라벨 데이터, 두 종류로 나뉜다. 1번 그림에서 보는 바와 같이 라벨이 붙어있는 데이터는 빙산의 일각이다.무수히 많은 언 라벨 데이터를 학습에 사용해야 하는데 어떻게 하면 학습에 도움이 되는 방향으로 데이터를 선택할 수 있을까?
4번 그림과 같이 모델이 가장 헷갈리는 (50%) 데이터를 이용하면 된다. 요약하면,, 언 라벨 데이터를 활용하는 방법입니다.
 Train 데이터를 5%단위로 증가 시킬 때, Active learnin의 효과를 관찰 할 수 있습니다.
Q. 75%부터 시작하는 이유는 라벨데이터로 모델을 만들어 두고 시작했기 때문인것 같습니다.
---
## python
<데이터분석 질문답변 & 친목 2019-02-13 (수)>
파이썬 list 데이터를 데이터 프레임으로 바꾸는 방법이 있을까요?
<답변내용> - 스스로 답변
Train 데이터를 5%단위로 증가 시킬 때, Active learnin의 효과를 관찰 할 수 있습니다.
Q. 75%부터 시작하는 이유는 라벨데이터로 모델을 만들어 두고 시작했기 때문인것 같습니다.
---
## python
<데이터분석 질문답변 & 친목 2019-02-13 (수)>
파이썬 list 데이터를 데이터 프레임으로 바꾸는 방법이 있을까요?
<답변내용> - 스스로 답변 ```python import pandas as pd a = [1,2,3] df = pd.Data.Frame(a) ``` 아마 질문자는 리스트가 아닌 다른 객체를 만들었거나, 판다스(pandas)를 inmport 안했던 것 같다.
예를들어 a가 리스트가 아닌 집합(set)인 경우 위 방식이 안먹힐 수 있다.
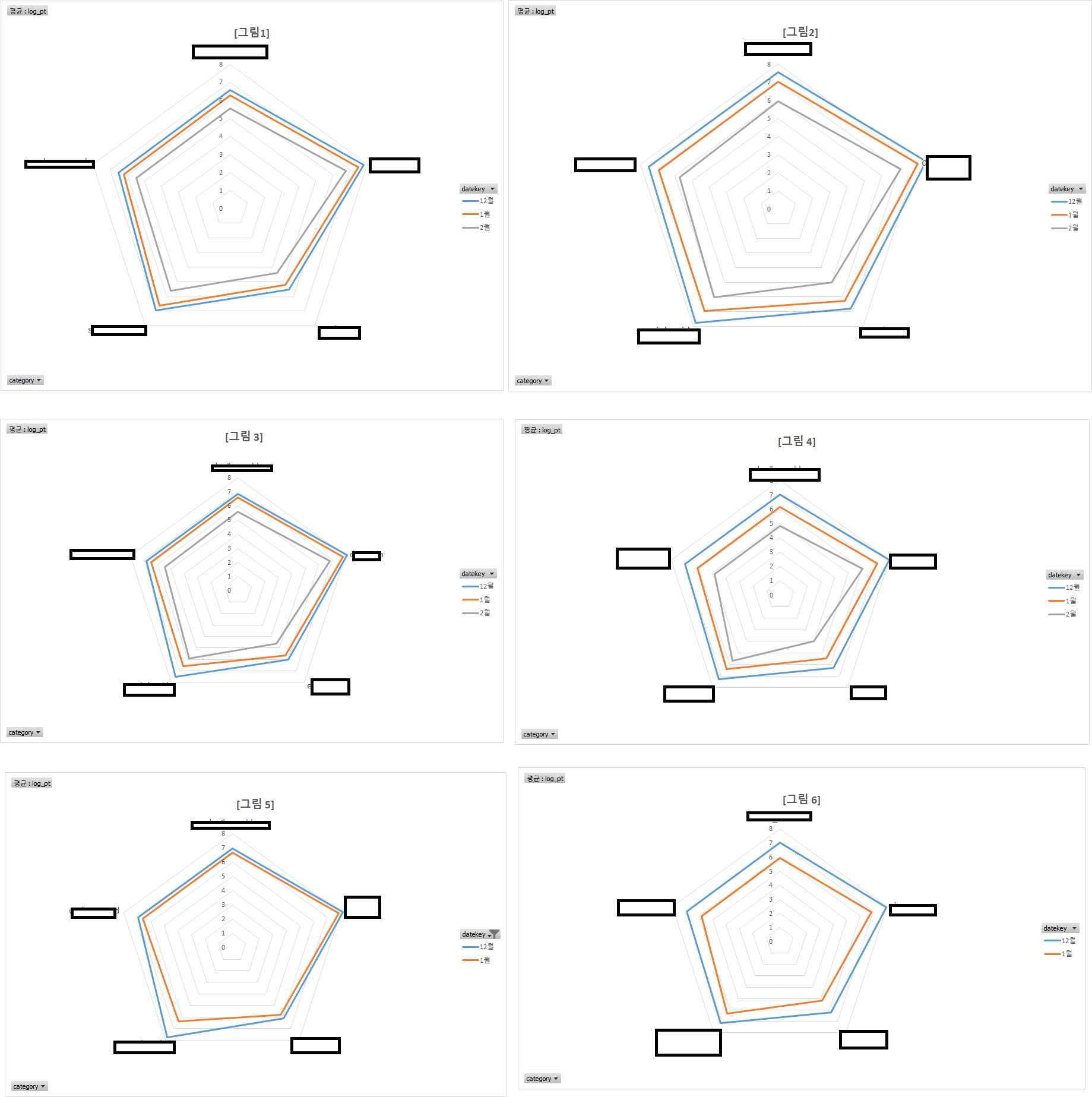
그럴 경우에는 적절한 변환이 필요하다. ```python a = {1,2,3] pd.DataFrame(list(a)) ``` --- ## 데이터 분석 <회사에서 격은="" 일=""> 나는 아래 사진을 다시 봤을 때, 오늘과 동일한 결론을 내릴 수 있을까?
먼저, 각 행은 어떤 스테이지를 클리어한 유저를, 열 중 좌측은 가입일자 대비 빠르게 클리어한 사람, 우측은 느리게 클리어한 사람이다.
1. 빠르고 느리고의 기준은 가입일로부터 클리어까지 걸린 평균일자보다 크고 작음이다 2. 선의 색은 가입 월을 의미 한다. 3. 도형의 크기(각 축의 숫자)는 유저의 평균 플레이 소비 시간이다. 예를들어 정 5각형이라면, 5개 콘텐츠에 동일한 시간을 소비하는 것이다. 이때, 좌우 유저 집단의 차이를 찾을 수 있는가
 ---
## python
- 지인 질문
python 판다스를 이용하다 보면 콘솔창에서 컬럼이 전부 출력되지 않는 모습을 자주 볼 수 있다.
---
## python
- 지인 질문
python 판다스를 이용하다 보면 콘솔창에서 컬럼이 전부 출력되지 않는 모습을 자주 볼 수 있다. 그럴때는 아래와 같이 설정하면 된다.
```python pd.set_options('display.max_columns', 변경하고 픈 숫자) ``` --- ## 패키지 질문
<케글 코리아 2019-03-10 (일)>
Apriori 연관성 규칙을 구하는 패키지가 있나요? 사실 질문에 답이 있었다. Apriori라는 패키지를 검색하면 된다.
Support(지지도): 사건이 일어나는 빈도
Confidence(신뢰도): A를 구매했을 때 B도 구매할 확률
Lift(향상도): 통계적으로 얼마나 유의미한 지표인지 (기준은 1)
자세한 내용은 지인 중 잘 정리해 둔 블로그가 있어 추천합니다. [슈퍼짱짱][슈퍼짱짱] [깃허브링크]: https://github.com/eat-toast/eat-toast.github.io/blob/master/_posts/2019-02-01-%20소심한%20나의%20답장.md [stackKST]: https://stackoverflow.com/questions/43518777/python-pytz-timezone-gives-just-same-as-utc-time [주피터 테마 변경]: https://towardsdatascience.com/bringing-the-best-out-of-jupyter-notebooks-for-data-science-f0871519ca29?fbclid=IwAR0ssGY0-_Yg8V9QUvRw3VBCxUBmFNQIX0c_zA31nOoDVgGV3qDedKjCcJk [슈퍼짱짱]: https://m.blog.naver.com/PostView.nhn?blogId=leedk1110&logNo=220788082381&proxyReferer=https%3A%2F%2Fwww.google.com%2F